The Six-Stage Prompt Chain
An Iterative Framework for GenAI-Powered Software Delivery
Abstract
Generative AI can accelerate software delivery, but without structure it magnifies chaos. This article targets CTOs, architects, tech leads, and product-minded engineers, proposing an iterative, knowledge-centric workflow where user manuals, BDD scenarios, design docs, and decision logs feed a chain of LLM prompts. By treating every micro-decision as reusable context, teams convert tribal memory into a compounding asset, aligning GenAI creativity with human judgment and Scrum cadence to ship code—and understanding—simultaneously.
1. Introduction – GenAI’s Litmus Test for Engineering Culture
Generative AI promises to write a function in the time it takes you to phrase a question. That raw speed is intoxicating and dangerous. When code arrives before context, teams accrue “AI-accelerated” rework, technical debt: duplicated logic, mismatched APIs, invisible assumptions. Velocity without structure merely spins the rework flywheel faster.
GenAI is effective only when it stands on unshakable fundamentals: a coherent architecture, friction-free developer experience, design clarity that exposes intent, and a relentless focus on user impact. Skip these basics and every AI suggestion amplifies entropy rather than value, turning quick wins into long-term liabilities.
The real opportunity is not faster code, but amplified knowledge. GenAI excels at recombining what a team already knows — architecture patterns, domain constraints, testing heuristics — into new solutions. The catch is that the knowledge must be explicit, current, and machine-readable.
In other words, GenAI adoption is a litmus test of engineering culture: do we capture decisions, or whisper them across desks? Do we treat documentation as a living asset, or an after-sprint chore?
This article presents an iterative, knowledge-centric workflow that turns micro-decisions into reusable prompts, couples human judgment with AI creativity, and delivers working software plus durable context every sprint.
We’ll outline six guiding principles, walk through a high-level process map, address organizational enablers, and show how the approach complements and extends the familiar cadence of Scrum.
By the end, you’ll see GenAI not as an autonomous coder but as a force-multiplier for teams disciplined enough to feed it the right fuel: well-curated human insight.
2. The Hidden Economy of Micro-Decisions
In software development every feature shipped is the visible tip of an iceberg made of countless tiny choices. Which edge case deserves a guard-clause? Should that API call be retried or queued? Is the loading spinner consistent with the design system? Each decision looks trivial in isolation, yet their aggregate weight determines whether a codebase feels elegant or exhausting. This invisible stream of micro-decisions is the real currency of software engineering.
When these choices stay in individual heads or half-remembered Slack threads, three problems emerge: context loss, cognitive drag, and compounding uncertainty. First, new team-mates or GenAI assistants must reverse-engineer intent from code alone, a process that is slow and error-prone. Second, senior engineers burn precious time re-answering questions they resolved months ago. Third, every undocumented trade-off invites accidental divergence: two developers solve the same problem differently, and the codebase fractures in style, performance, or security posture.
GenAI tools amplify both the opportunity and the risk. A well-prompted model can surface library conventions, predict edge cases, and propose idiomatic patterns in seconds — but only if the rationale behind earlier decisions is explicit and machine-readable. Feed the model incomplete context and it will hallucinate assumptions, hard-coding yesterday’s workaround into tomorrow’s technical debt. Because an LLM is optimized to be helpful, it refuses to leave blanks; when humans abdicate responsibility for “obvious” details, the model cheerfully fabricates them — selecting default time-outs, inventing error messages, or picking naming conventions that never existed.
Treating micro-decisions as first-class artifacts flips this dynamic. Architectural and other technical design documents, lightweight decision logs, and BDD scenarios transform tacit knowledge into a reusable prompt library. The payoff compounds: engineers regain cognitive bandwidth, onboarding accelerates, and GenAI shifts from speculative guesswork to informed collaboration — turning the hidden economy of micro-decisions into a visible, investable asset.
Example to Illustrate the Volume of Small Decisions Software Developers Make
When building modern products, software engineers routinely make dozens—if not hundreds—of small yet consequential decisions. Consider something as seemingly straightforward as rendering a list of teams in a frontend component. A simple <DataTable> component, such as the one below, offers a glimpse into the decision-making involved:
<DataTable
:value="teams"
v-model:selection="selectedTeam"
selectionMode="single"
dataKey="id"
:paginator="teams.length > 10"
:rows="10"
:filters="filters"
filterDisplay="menu"
:globalFilterFields="['name', 'description', 'teamManagerName']"
stripedRows
responsiveLayout="scroll"
class="teams-table"
:rowClass="(data) => `team-row team-row-${data.id}`"
@rowClick="$emit('rowClick', $event.data.id)">
At first glance, this configuration might appear routine. But each line reflects a deliberate decision, made within a broader context of user needs, business rules, technical constraints, and UI conventions:
- Filtering: Should filtering appear inline with each column or in a centralized menu? Should it support global text search across multiple fields?
- Pagination: Should pagination always be on, or only when the dataset exceeds a threshold? Is client-side pagination enough, or is server-side pagination needed for scalability?
- Row Selection: Should the user be able to select one row or many? Should selection trigger a dialog, route change, or inline expansion?
- Event Handling: Should a row click event be used or explicit action buttons instead?
- Event Emission: How should the component communicate selection events back to its parent - via an event bus, prop-based callbacks, or emitted events?
- Class Naming and Styling: Should the row styling reflect domain-specific states, like a
team-row-activeorteam-row-archivedclass? What CSS strategy governs these choices? - Responsiveness: Should the layout collapse gracefully on mobile? Should columns auto-wrap, or become horizontally scrollable?
- Consistency with Other Tables: If another table in the same app (say, for People management) uses different filtering (e.g.,
filterDisplay="row"), should this one match for consistency, or intentionally differ to match domain-specific use cases?
Even these are just surface-level questions. Each answer carries further implications: performance trade-offs, accessibility concerns, onboarding cost for new team members, and even downstream effects on analytics or testing strategies.
This is the invisible cognitive workload of software engineering: a constant stream of micro-decisions, each too small to seem significant in isolation, but collectively shaping the reliability, usability, and maintainability of the product.
By examining just one table component, we uncover a hidden layer of complexity that developers manage daily—often under tight deadlines and shifting requirements. Understanding this mental landscape is essential not only for appreciating the craft of software development but also for designing better tools, workflows, and metrics to support developer productivity and decision quality.
From a knowledge work perspective, each of these small decisions represents the resolution of a local uncertainty—an act of applying domain knowledge, interpreting requirements, and reconciling trade-offs. The sheer number of such decisions is what makes software development a high-intensity knowledge activity. Importantly, most of this decision-making remains tacit: embedded in code, dispersed across commits, or confined to the heads of individual developers. This poses a significant challenge when using large language models (LLMs) for tasks like code generation, review, or maintenance. LLMs perform best when the rationale behind architectural and implementation choices is made explicit and accessible in a structured form. If decisions such as filter types, event-handling strategies, or UI consistency patterns are not documented—or worse, if they are inconsistently applied—LLMs must guess context from incomplete cues, leading to brittle or misaligned code suggestions. Therefore, capturing these micro-decisions in a way that LLMs can parse—through meaningful commit messages, structured comments, configuration schemas, or design annotations—is essential. Doing so not only improves the effectiveness of AI-assisted development but also strengthens the collective memory and coherence of the engineering team itself.
To contrast decisions with judgments in the context of software development and decision theory: decisions typically involve selecting from a known list of options - like choosing between filterDisplay="row" or "menu", a filter type, pagination strategy, or event-handling mechanism. These are classic decision-theoretic situations where options are defined, and the task is to evaluate and pick the best one.
In contrast, judgments arise when the available options are not clearly defined or even known in advance. Developers must first discern what the relevant options even are - such as when inferring user needs from ambiguous requirements, predicting future performance bottlenecks, or determining the appropriate abstraction level in a new module. These are acts of sensemaking, not selection.
Judgment is foundational in knowledge work because much of the uncertainty lies in framing the problem itself, not merely solving it. Without good judgment to structure the space of alternatives, even the most rational decision-making process will fail to deliver meaningful outcomes.
3. Knowledge-Centric Principles for GenAI Workflows
GenAI thrives when it stands on a well-curated stack of human judgement. The following six principles convert that judgement into a stable launchpad for iterative, AI-assisted delivery.
1. Growth Order – Plant the Tree in the Right Soil
Good code grows from good context. Establish artifacts in a deliberate sequence: user manual → BDD scenarios → technical design → implementation plan → code. Each layer enriches the prompt context for the next, so the model receives a steadily widening frame of reference. Skipping steps forces GenAI to guess, breeding brittle patches and rework cycles.
2. Planning as Grounding – Turn Fuzzy Ideas into Testable Promises
Before invoking a single code-generation prompt, capture the user’s intent as concrete, verifiable statements - E2E tests, acceptance criteria, performance budgets. These artifacts anchor the system; they are both the rails that keep GenAI on track and the yardsticks that prove it delivered value. Planning is no longer a phase gate; it is the grounding ritual that aligns human vision and machine execution.
3. Context Is King – Elevate Documentation from Afterthought to Input
Traditional docs explain the past; in a knowledge-centric flow they shape the future. Well-structured WiKis, architecture decision records, and inline comments feed directly into model prompts, letting GenAI reuse past wisdom instead of reinventing it. Investing ten minutes in context can save hours of speculative prompting.
4. Human-in-the-Loop Guardrails – Delegate, Don’t Abdicate
GenAI excels at pattern synthesis and boilerplate, but judgment on business risk, ethics, and non-functional trade-offs remains human terrain. Define clear boundaries — security policies, architectural principles, regulatory constraints — and teach the model to operate inside them. Regular checkpoints (code review, design review, test review) ensure that if the AI drifts, the loop snaps shut before defects escape.
5. Control Through Narrative – Tell the Story as You Build It
Narrative artifacts — decision logs, commit messages, design diagrams — form an evolving storyline the whole team (GenAI included) can follow. When every change answers the question “Why now, and why this way?” the workflow becomes self-documenting, onboarding accelerates, and future prompts gain richer texture.
6. Process over Heroics – Systematize Success
High-performing teams don’t rely on memory or midnight heroes; they rely on repeatable processes that make the desired behavior the path of least resistance. Encode each interaction — prompt patterns, review checklists, deployment gates — so improvements stick and knowledge compounds. Process is not bureaucracy; it is institutional memory with an MCP server in front.
Together, these principles transform GenAI from a clever autocomplete into a collaborative partner — one that scales human expertise instead of diluting it.
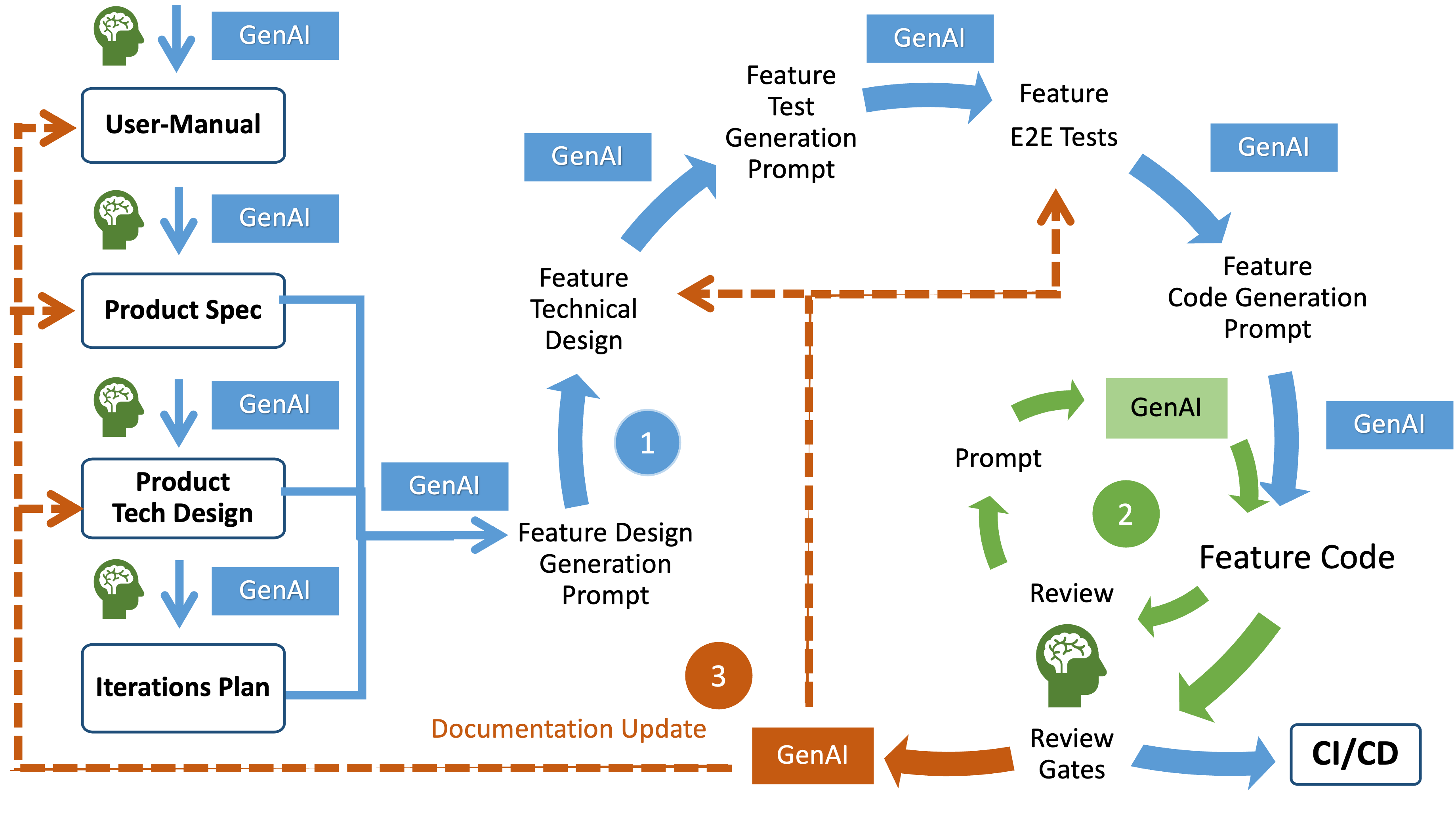
4. The Iterative GenAI Workflow (High-Level)
The workflow pairs an incremental delivery cadence with a compounding-knowledge backbone. Think of it as a six-stage flywheel: each lap yields shippable value and enriches the next lap’s prompt context.
0 Foundations — Prepare the Soil
Before the first prompt, the organisation establishes non-negotiables: architecture guardrails, security policies, coding standards, and a friction-free developer-experience stack (CI, automated tests, code-review gates). These boundaries replace open-ended “best effort” with a stable playing field that GenAI can safely roam.
1 User-Manual Draft — Capture Intended Behaviour
A product owner or UX lead seeds GenAI with high-level goals, personas, and user journeys. The model returns a draft manual: features, flows, edge-case questions. Humans answer clarifications; GenAI refines. Output lives in version control, tagged to product epics. Feedback loop: stakeholder review ensures the manual still reflects business value after each iteration.
2 Product Spec as BDD Scenarios — Make Behaviour Executable
The team now converts manual prose into Behaviour-Driven Development (BDD) scenarios — positive paths, failure modes, performance constraints. GenAI can draft the Gherkin syntax (Feature, Scenario, Given, When, Then) skeleton; then domain experts assert correctness. These scenarios become the ground truth for both test generation and future prompts.
3 Product Technical Design — Map Solution Space
Prompt GenAI with the scenarios plus architectural constraints. It proposes component diagrams, data flows, API contracts, and tech options. Architects validate, prune, or extend. Approved designs are committed alongside ADRs (Architecture Decision Records), turning design rationale into machine-readable context.
4 Product Implementation Plan — Slice Work into Iterations
GenAI scans the BDD scenarios and design artefacts to draft a feature-by-feature implementation roadmap: it groups related BDD scenarios into iterations, surfaces cross-cutting dependencies, and flags the sequencing between iterations. Tech leads may re-rank for risk or business priority, but the initial plan helps avoid human blind spots such as hidden coupling.that humans often miss. Crucially, this plan is not static documentation — it is the control file we feed back to the model, instructing the LLM to work through the backlog iteration-by-iteration and feature-by-feature, always operating with the right slice of context.
5 Iterative Cycle — Build, Test, Refine
Features are organized hierarchically as:
- Iteration → Feature → Scenarios
- All scenarios within a feature share the same BDD spec file
- All scenarios within a feature should be designed and implemented together as a cohesive unit
Features flow through a disciplined, prompt-centric pipeline. The mantra is “generate → review → approve → reuse.” Each lap locks in a reusable context and pushes risk to the smallest safe slice.
| Stage | Output | Who Does What? | How GenAI Is Used | Capture & Traceability |
|---|---|---|---|---|
| 0. Feature Technical Design | BDD spec file (shared by all scenarios) | Architects and other technical experts verify design | GenAI prepares the document based on the User Manual, Product Specification, Product Technical Design and Product Implementation plan | Design lives in VCS |
| 1. Feature Implementation Plan | Feature Tasks Breakdown grouped by UI / Service Integration / Validation / Error Handling / State Management / Accessibility & Selectors / Testing | LLM drafts; team guides & reviews; LLM edits; final plan approved | Produces the plan prompt ➞ stored | Approved plan overwrites draft |
| 2. Test Generation Prompt | Human-readable prompt that instructs the next LLM call to create E2E tests from the BDD spec | LLM drafts; team reviews/edits via LLM; final prompt approved | Prompt fed back to LLM to produce E2E test files | Tests + prompt committed to VCS |
| 3. Code Generation Prompt | Prompt that bundles plan, tests, and guardrails | LLM drafts; team reviews/edits via LLM; final prompt approved | Prompt fed back to LLM to produce working code | Code committed to VCS |
| 4. Refactoring (Vibe Coding) | Exploratory refactor suggestions | Devs converse with LLM in short loops | LLM proposes tweaks; humans steer | Only final diff + ADR-style summary (authored by LLM) committed to VCS |
| 6. Review Gates | CI, static-analysis, security scans, code review | Automated checks + human PR | Failing gates generate new LLM tasks or spec tweaks | Gate results logged |
| 5. Documentation Update Prompt | Prompt describing doc changes needed to keep manual, BDD, design docs in sync | LLM generates from commit diff & PR discussion; team sanity-checks; team reviews/edits; prompt approved | Prompt fed back to LLM to produce updates to the User Manual, Product Specification, Product Technical Design and Product Implementation plan | Docs + summary committed to VCS |
Key mechanics
- Hierarchical cohesion. Work is always sliced Iteration → Feature → Scenarios; all scenarios in a feature ship together to avoid orphan edge cases.
- Sequential prompt chain. Each approved artifact is itself the next prompt’s core context, ensuring the model always works within an up-to-date frame.
- Human judgment at checkpoints. Approval gates exist after every prompt — plan, test-prompt, code-prompt, doc-prompt — to calibrate trust and inject constraints. Edits are performed through the LLM, not in a separate tool, so the knowledge remains machine-readable.
- Transient exploration, permanent intent. Vibe-coding style chats vanish once the final refactor merges; what persists is the commit diff and its LLM-authored decision summary.
- Living knowledge base. Specs, plans, prompts, tests, code, docs, and ADRs all live side-by-side in version control, giving future LLM calls a rich, authoritative context.
This loop repeats feature-by-feature inside each iteration until the Definition of Done — including knowledge capture — has been satisfied, compounding context and confidence with every pass.
6 Knowledge Capture — Close the Loop
Every merge triggers a summarisation step: GenAI distils commit messages, decision logs, and test outcomes into a concise record. These summaries seed future prompts, accelerating subsequent iterations and onboarding. Over time the repository evolves into a living “prompt library” where past wisdom is one semantic-search away.
5. Organizational Enablement – Culture, Incentives, Governance
GenAI-accelerated delivery is ultimately a mirror held to an engineering organization: it reflects your culture, magnifies your incentives, and exposes gaps in governance. To sustain a knowledge-centric workflow, four levers matter most.
Culture – Valorise explicit knowledge over tribal memory.
Celebrate developers who leave a clear paper trail of why as much as what. In stand-ups, ask “Which decisions did we capture yesterday?” alongside “What did we ship?” Make prompt files, ADRs, and design sketches first-class artifacts visible to everyone, not dusty attachments at sprint’s end. When explicit rationale is the social norm, GenAI always has fresh context and new hires ramp in days, not weeks.
Incentives – Reward clarity, not heroics.
Tie promotion criteria and sprint-review kudos to clear commit messages, thorough design annotations, and up-to-date docs. Recognise the engineer who prunes a prompt for precision or writes a crisp decision summary; that invisible work compounds team velocity. Conversely, treat undocumented quick fixes as defects, not victories.
Governance – Embed context checks in the pipeline.
Add lightweight gates that fail a merge if a feature lacks its BDD spec, prompt chain, or decision log. Static analyzers can flag TODO comments without linked tasks; bots can nudge for missing ADRs. The goal is guidance, not bureaucracy: automated reminders that nudge behaviour long before audit day.
Leadership – Sponsor continuous improvement of AI guardrails and tooling.
Budget time for refining prompt libraries, upgrading semantic-search indexes, and tuning security constraints. Fund “prompt retros” the way you fund test-coverage drives. When executives champion these hygiene tasks as strategic investments, teams stop viewing them as overhead and start seeing them as the runway that lets GenAI lift the organization higher.
6. How the Workflow Complements (and Extends) Scrum
| Scrum Concept | Knowledge-Centric GenAI Twist |
|---|---|
| Sprint | Cadence stays fixed, but each sprint must ship artifacts (prompts, ADRs, test suites) alongside working software. Velocity now measures knowledge captured, not only story points or hours burned. |
| User Story | A story is incomplete until it is expressed as BDD scenarios and logged design decisions, giving the LLM deterministic context instead of vague acceptance criteria. |
| Definition of Done | Adds a “context captured” gate: code cannot close unless its prompt chain, tests, and decision summary are committed and pass automated checks. |
| Roles | The core team remains PO, Scrum Master, Developers but Developers are augmented by a GenAI Agent that they steer. The Tech Lead assumes “prompt librarian” duties, curating guardrails and reusable prompts. |
Scrum and the iterative GenAI workflow share the same heartbeat of short, inspect-and-adapt cycles; the difference lies in what gets inspected.
A Sprint Review now showcases not only a demo of running features but also the knowledge assets that will power the next sprint’s LLM calls. Sprint Planning draws on version-controlled prompts and ADRs to refine effort estimates.
Retrospectives include a “prompt hygiene” check: were guardrails clear, did any hallucinations slip through, which micro-decisions went undocumented? By extending Scrum’s artifacts and ceremonies to include explicit context for GenAI, we preserve its empirical control while unlocking AI-accelerated delivery—without disrupting the familiar rhythm that teams already trust.
7. Common Pitfalls & Anti-Patterns
1. “Prompt-and-Paste” coding.
Grabbing the first GenAI snippet that compiles and pasting it into the repo — without updating BDD specs, design docs, or decision logs — creates a split-brain codebase. Context drifts, future prompts misfire, and onboarding slows to a crawl.
2. Skipping the Growth Order.
When a team jumps straight to code generation before drafting tests or technical design, GenAI fills the vacuum with guesses. The initial time saved resurfaces as rework: flaky tests, mismatched APIs, and architectural backtracking that could have been avoided by honoring the user-manual → BDD → design sequence.
3. Over-automation that sidelines judgment.
Treating the LLM as an autonomous engineer — auto-merging refactors, bulk-editing docs, rewriting tests — removes the human sense-check that catches subtle business rules, compliance constraints, and nuanced trade-offs. Automation should accelerate decision-making, not replace it; deliberate approval gates keep responsibility where it belongs.
8. Conclusion & Next Steps
GenAI is a litmus test: it instantly spotlights teams that curate knowledge and exposes those that rely on tribal memory.
By embracing an explicit, prompt-centric workflow — grounded in Growth Order, human guardrails, and artifact-driven sprints — organizations turn micro-decisions into a renewable asset rather than silent risk.
Start small: pilot the framework on a single feature set, track how many decisions are captured versus re-explained, and measure rework hours before and after. The data will speak louder than any slide deck.
In upcoming articles we’ll share actionable checklists, reference prompt libraries, tooling deep-dives, and the finalized workflow diagram to help you scale this approach with confidence.

Dimitar Bakardzhiev
Getting started


